



The Independent Sentinel #51
Un asesor de aprendizaje, el poder de la inferencia y renderización neuronal

¡Hola! Soy Javier Fuentes, gracias por estar leyendo esta nueva edición de The Independent Sentinel, la newsletter que habla sobre Inteligencia Artificial escrita sin usar Inteligencia Artificial.
Si quieres que cada nueva publicación te llegue directamente a tu correo electrónico puedes suscribirte aquí:
Hoy hablamos de asistentes de aprendizaje, del poder de la inferencia y del videojuego que creó una industria multimillonaria.

¡Comenzamos! 🚀
1. Tendencias 📈
🔬 Un asistente para la investigación
Hace apenas unos días, Google nos dejó a todos boquiabiertos al lanzar la nueva versión de un producto que ya habían lanzado en 2023: NotebookLM.
NotebookLM es una sofisticada aplicación de notas potenciada con IA para hacer que la investigación y el aprendizaje sobre cualquier tema sea más sencillo. Para ello, es posible crear una “base de conocimiento” con la que poder conversar y discutir sobre el tema en cuestión.
Además de mejorar las capacidades conversacionales y la interfaz, en esta nueva version Google ha incluido una nueva funcionalidad que hace intuir que la compañía californiana aún guarda muchos ases en la manga en lo que a IA Generativa se refiere.
Esta nueva funcionalidad es la de poder crear un podcast a partir de la base de conocimiento facilitada al programa. La calidad del podcast generado es realmente destacable, tanto en el fondo (el guión), como en la forma (las voces de los dos interlocutores). Esta inesperada funcionalidad da pistas de cómo nuestras interacción con la maquinas serán mucho más sencillas, efectivas y amigables.
Merece la pena dedicar unos minutos a escuchar esta creación de una IA en la que dos personas que no existen hablan de The Independent Sentinel usando la documentación sobre las distintas ediciones de la newsletter que he subido a NotebookLM. Sin duda, estamos viviendo en el futuro.
Además de esta increíble capacidad, la funcionalidad base de NotebookLM es igualmente excelente, cualquier pregunta, resumen o apreciación sobre la base de documentación (es capaz de aceptar hasta 50 fuentes distintas).
No pude resistir la tentación de preguntar al modelo acerca de su opinión sobre The Independent Sentinel, y esto fue lo que me respondió:
"The Independent Sentinel" is a newsletter authored by Javier Fuentes. The newsletter aims to make complex topics in these fields accessible to a broader audience by combining accessible explanations, engaging historical context, and a focus on practical applications.
Key Themes and Features:
● Demystifying AI and Data Science: The newsletter consistently breaks down intricate concepts into digestible explanations, using clear language and relevant examples. This approach makes it a valuable resource for individuals with a general interest in the field who may not possess deep technical expertise.
● Bridging the Past and Present: "The Independent Sentinel" excels at connecting current advancements in AI and data science to their historical roots. This historical framing provides valuable context for understanding the trajectory of these fields. For instance, the newsletter features profiles of influential figures like Norbert Wiener, the father of cybernetics, and recounts significant historical events like the 1860 "Great Debate" through a data science lens.
● Real-World Applications and Implications: The newsletter goes beyond theoretical discussions to highlight the tangible ways in which AI and data science are impacting the world. It covers diverse applications like drug discovery, investment algorithms, agricultural advancements, and the potential of AI to automate tasks in a future metaverse.
● Ethical and Philosophical Considerations: Fuentes doesn't shy away from addressing the broader societal and ethical implications of AI. The newsletter grapples with complex questions about consciousness in the context of AI, the potential dangers of increasingly powerful models, and the need for guidelines to shape the behavior of AI systems.
● Showcasing Emerging Trends: "The Independent Sentinel" keeps readers abreast of the latest trends and breakthroughs in AI and data science. For instance, the newsletter provides insights into the development and impact of large language models like ChatGPT and GPT-3, and the emergence of techniques like "ControlNet" that offer greater control over AI image generation.
● Engaging and Accessible Format: The newsletter employs a consistent format with clear headings, concise paragraphs, bullet points, and bold text to enhance readability. The inclusion of a table of contents in some of the longer issues further improves navigation.
Overall Impression:
Based on the provided excerpts, "The Independent Sentinel" emerges as a well-written and thought-provoking publication that offers a valuable perspective on the evolving landscape of AI and data science. Its blend of technical explanations, historical context, and philosophical exploration makes it an engaging resource for anyone seeking to understand this rapidly developing field and its potential impact on society.👉🏻 Si quieres acceso al Notebook sobre The Independent Sentinel para hacer consultas, mándame un mensaje por email y te doy acceso ya que, por ahora, NotebookLM no permite dar acceso público.
Como indicaba, parece que Google no está tan muerto como se podía pensar y que aún tiene mucho por mostrar. Basta escuchar a las predicciones que Eric Schmidt, el ex CEO de la compañía, lanzó hace unos días en un evento:
Cómo habrás podido oír parece que la llegada de ventanas de contexto ilimitadas y los esperadísimos agentes están mucho más cerca de lo que pensamos.
🔎 El poder de la inferencia
En el mundo dela Inteligencia Artificial, los conceptos de entrenamiento e inferencia son fundamentales para entender cómo funcionan los modelos.
Podemos describir el entrenamiento como el proceso algorítmico por el que un modelo es capaz de aprender a realizar una tarea a partir de un conjunto de datos, mientras que la inferencia es el proceso de utilizar el modelo (ya entrenado) para realizar predicciones o clasificaciones sobre datos nuevos.
Un ejemplo sencillo para entender estos conceptos sería un modelo de clasificación de imágenes que puede identificar si una imagen contiene un perro o un gato:
Entrenamiento: Le das al modelo miles de imágenes etiquetadas como "perro" o "gato". El modelo ajusta sus parámetros para identificar características distintivas de perros y gatos.
Inferencia: Después del entrenamiento, le das una nueva imagen, y el modelo hace una predicción (por ejemplo, "perro").
Hasta ahora y desde un punto de vista computacional, el proceso de entrenamiento ha sido significativamente mucho más costoso que el proceso de inferencia:
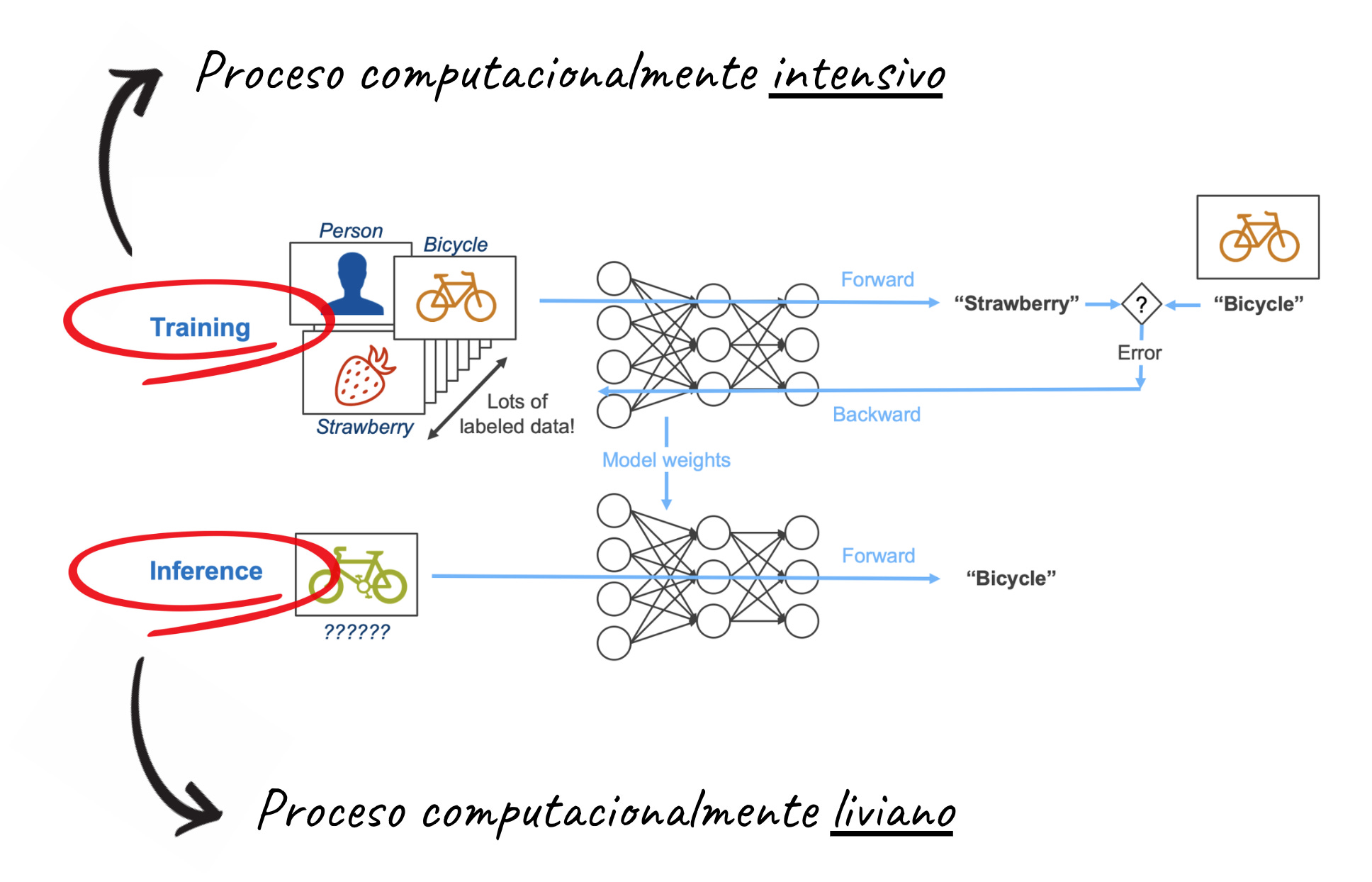
Pero esto está cambiando. No me refiero a que la inferencia necesite de más recursos que el entrenamiento (estamos hablando de varios órdenes de magnitud de diferencia) sino que, tal y como comentaba en el ultimo monográfico (TIS#50), parece que dedicando más computación a la inferencia se pueden conseguir mejores resultados.
En estos nuevos modelos razonadores como el recientemente presentado o1, la inferencia consume más tiempo que en los modelos anteriores como GPT-4o, ya que, en esta fase, se realiza un proceso de búsqueda y reflexión (“razonamiento”) para encontrar mejores respuestas a las preguntas planteadas.
La pregunta es, ¿dónde está el límite de mejora si decidimos aplicar más computación a la inferencia?
Recientemente, se publicaba un paper a este respecto elaborado por autores de Stanford, Google y Toyota en el que hablan de estos límites, y lo más interesante de todo es que se ha probado matemáticamente que la arquitectura Transformer pueden solventar cualquier problema siempre y cuando se puedan generar tantos tokens de razonamiento intermedio como se necesiten.
Dicho de otro modo, se ha demostrado que los transformes son capaces de abordar cualquier problema siempre y cuando se dedique la suficiente computación en inferencia.
La principal innovación del nuevo modelo o1 de OpenAI es que mejora su razonamiento, no a través de redes más grandes y costosas de entrenar, sino dedicando más tiempo de computación a “pensar” en la respuesta.

Este nuevo enfoque está abriendo un camino interesantísimo sobre cómo seguir construyendo mejores modelos que. nos permitan acercarnos al nivel de inteligencia que todos esperamos.
2. Historias 📔
🎼 ¿Quieres banda sonora? ¡Dale al Play!
📅 Un año de la década de los 90
Como en casi todos los años, en 1993 pasaron muchas cosas: entró en vigor el Tratado de Maastricht que dio el pistoletazo de salida a la Unión Europea, Clinton llegó a la Casa Blanca, Nirvana publicaba su álbum In Utero justo antes de la muerte de Kurt Cobain, Roberto Baggio ganaba el Balón de Oro, se “retiraba” Michael Jordan y se estrenaba Parque Jurásico. Casi nada.

Para finales de ese año, y cuando parecía que ya no podían pasar más cosas, el 10 de Diciembre de 1993 se publicaba un videojuego que cambiaría por completo la incipiente industria del ocio electrónico.
Déjame que te cuente esta historia.
👦🏼 Un enfant terrible
John Carmack no tuvo una infancia fácil pero pese a ello supo desde muy pequeño que su pasión eran los ordenadores y la programación.
Carmack nació en Kansas City (Missouri) en 1970 y desde muy pequeño estuvo obsesionado con los juegos y la ciencia-ficción. Como ya te podrás imaginar, su juego favorito era Dungeons & Dragons hasta que las computadoras se cruzaron en su camino.
John siempre quiso tener su propio ordenador, pero las circunstancias económicas de su familia no eran las más favorables para ello. Tal era su deseo que, junto a unos amigos, decidió robar un ordenador de un un colegio cercano ubicado en un barrio más próspero. Y no, no fue algo fácil, Carmack se las ingenió para acceder al instituto usando una creativa mezcla de termita y vaselina para forzar la puerta.

Todo estaba saliendo bien en su plan hasta que todo empezó a ir mal y es que Carmack y sus compinches acabaron siendo arrestados, lo que llevo a John a pasar un año en un centro de menores.
Este año recluido no hizo más que aumentar su rebeldía y su pasión desmedida por la computación. Tan es así que a su regreso a casa pasó incontables horas aprendiendo sobre ordenadores y programación. Pese a los intentos de sus padres para que John completase sus estudios, su brillantez e inquietud intelectual le acabaron haciendo dejar la formación reglada tras unos meses estudiando informática en la Universidad de Missouri.
Después de abandonar sus estudios consiguió su primer trabajo en una pequeña empresa de software llamada SoftDisk ubicada en Louisiana. Allí conoció a unos tipos tan apasionados por la informática como él: John Romero, Tom Hall y Adrian Carmack (sin parentesco alguno).
Carmack y sus compañeros creaban juegos para SoftDisk durante el día, pero al acabar la jornada, cogían todo el hardware de la oficina para seguir en casa trabajando y experimentando.
Durante este periodo, Carmack y sus compañeros lograron recrear una demo jugable de Super Mario Bros. 3 replicando el scroll horizontal del juego y usando su personaje “Dangerous Dave” en vez de Mario.
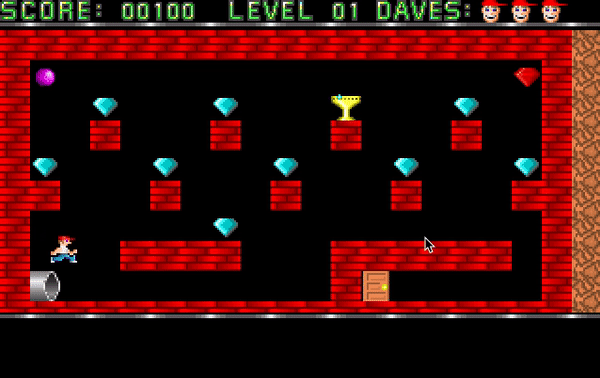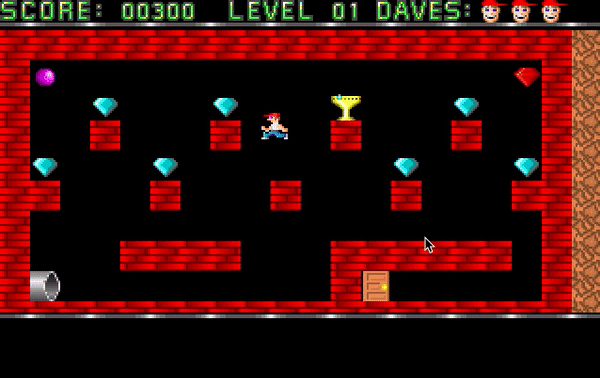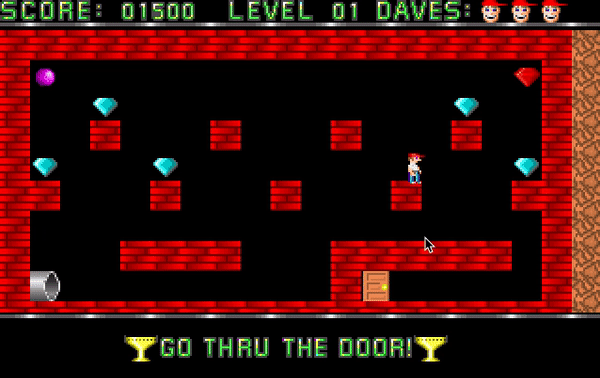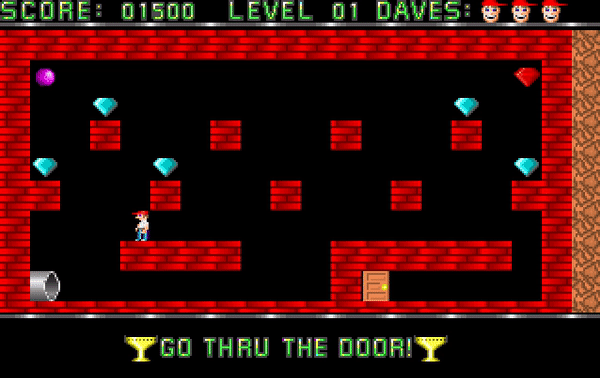
Llegaron incluso a mandar su trabajo a Nintendo que les respondió alabando su habilidad pero, advirtiéndoles en la misma misiva, de que estaban violando la propiedad intelectual de Nintendo y que debían parar inmediatamente con ese desarrollo.
Todo este esfuerzo cristalizó en su primer juego exitoso en 1990. El juego se llamaba Commander Keen 1: Marooned on Mars y se distribuyó como shareware, nombre que se usaba por aquel entonces para los modelos de distribución freemium.

El juego resultó ser un éxito, así que Carmack decidió abrir su propia compañía de juegos junto con su compañero John Romero.
La empresa se llamaba id Software y la leyenda estaba a punto de empezar.
💾 Una empresa de videojuegos diferente
En 1991, los Carmack (John y Adrian) junto con John Romero contrataron a varios ingenieros más y empezaron a trabajar en su nueva empresa.

El videojuego favorito de Carmack desde niño era un juego llamado Castle Wolfenstein, desarrollado por Silas Warner en 1981 para el Apple II, el Atari de 8 bits, el Commodore 64 y MS-DOS.
El juego consistía en ponerse en la piel de un prisionero aliado en la II Guerra Mundial que debía escapar de una prisión nazi ubicada en el castillo de Wolfenstein.
Inspirados por este videojuego, los integrantes de la recién creada compañía quisieron llevar a este clásico a nuevas cotas de diversión y tenían pensado hacerlo de un modo que nadie aún habían hecho: renderizando entornos 3D y usando la tecnología de scrolling que habían aprendido replicando Mario Bros.

El juego, llamado Wolfenstein 3D fue un auténtico éxito. Supuso una revolución en aquel momento: Movimientos completos en el eje horizontal, capacidad de apuntar, multitud de armas y jefes finales inolvidables. Había nacido un género: el FPS (First Person Shooter).

id Software revolucionó por completo el sector con este nuevo tipo de juegos en 3D, pero su historia estaba empezando a arrancar.
👹 Un icono de la cultura popular
Tras el éxito de Wolfenstein 3D, el joven estudio tenía ganas de cosechar más éxitos. Y vaya que si lo hicieron. Apenas un año y medio después, id Software lanzaría el videojuego que les catapultaría, definitivamente, a la fama: Doom.
En Doom, tomábamos el papel de un Marine Espacial en su travesía desde las lunas de Marte al Infierno batallando con todo tipo de muertos vivientes, demonios y otros engendros. El juego mezclaba de manera magistral elementos gore, de ciencia-ficción y de acción en un gameplay insultantemente divertido. id Software lo había vuelto a hacer.

El juego fue lanzado originalmente para MS-DOS el 10 de diciembre de 1993, y más tarde se trasladó a numerosas plataformas, incluyendo consolas modernas, estableciéndose como uno de los juegos más influyentes de todos los tiempos y sentando definitivamente las bases para el género incipiente de los shooters en primera persona.

El modelo shareware que tan bien les funcionó con Commander Keen fue el elegido también para el lanzamiento de Doom. id Software ofreció de manera gratuita el primer episodio, teniendo que pagar aquellos que quisieran disfrutar del juego entero.
Esta fue una jugada maestra por parte del estudio, ya que la demo se viralizó como la pólvora por todo el mundo y dio al videojuego un puesto de honor en el Olimpo del entretenimiento electrónico.
👉🏻 Un apunte interesante. Según el propio Carmack, Doom es un “Turing Complete Design Space”, lo que hace que, aún a día de hoy, haya gente diseñando niveles para el juego ya que ofrece posibilidades creativas “ilimitadas”. A modo de ejemplo, algo similar pasa con juegos como Minecraft.
El concepto de "Turing Complete Design Space" se refiere a un conjunto de sistemas, lenguajes o mecanismos de diseño que tienen la capacidad de ejecutar cualquier algoritmo computacional que pueda ser realizado por una máquina de Turing. Este concepto surge del trabajo de Alan Turing sobre la teoría de la computabilidad, en la que una "máquina de Turing" es un modelo abstracto capaz de simular cualquier proceso computacional.
Si quieres conocer de primera mano la historia de Doom, te recomiendo esta entrevista de lex Friedman con el propio Carmack.
El último hito del estudio llegaría en 1996 cuando lanzaron una versión más refinada, sofisticada y cuidada de esta tipología de juegos. El juego se llamaba Quake y, por primera vez, daba la opción de apuntar y moverse en horizontal y vertical.
Además, introdujo un nuevo modo de juego (llamado “Deathmatch”) que acabaría dando lugar a los videojuegos FPS multijugador tan populares hasta el día de hoy.

👨🏻💻 Carmack: El ingeniero todoterreno
A pesar de ser multimillonario desde los 90, Carmack nunca ha dejado de trabajar. De hecho, se considera a sí mismo un “workaholic”.
Además de los videojuegos, Carmack ha tenido siempre pasión por cohetes. Como muestra, en el año 2000, invirtió varios millones en crear una enorme nave industrial y un campo de pruebas en Mesquite (Texas) para alojar su nueva empresa: Armadillo Aerospace.
El objetivo de Carmack no era otro que construir naves suborbitales para llevar turistas al espacio en primer termino para, eventualmente, llevar a cabo viajes espaciales más ambiciosos.

Pese a ganar varios concursos, la compañía acabó cerrando en 2013 tras algunos sonados fracasos. No obstante, Carmack ha dejado la puerta abierta a que, en algún momento, Armadillo reabra sus puertas.
En 2013, dejó también definitivamente id Software y fue fichado como CTO por OculusVR, la empresa de dispositivos de realidad virtual que sería finalmente comprada por Meta y sirvió como punto de partida para los dispositivos Meta Quest que todos conocemos.
Actualmente, y desde 2022, Carmack trabaja en una compañía llamada Keen Technologies fundada por él mismo y dedicada, como no podía ser de otra manera, a la inteligencia artificial.
🖥 La prueba de fuego para los computadores
Volvamos de nuevo a Doom. Debido a la versatilidad infinita del juego, su popularidad se ha mantenido en el tiempo y podríamos decir que el juego se ha convertido en una leyenda.
Más allá del juego en sí, Doom se acabó convirtiendo en una obsesión para hackers de todo el mundo ya que ejecutar el juego en los dispositivos más insospechados se convirtió en un símbolo de conocimiento, estatus y prestigio en el mudo del hacking.
Veamos alguno ejemplos para comprobar el nivel de locura al que nos estamos refiriendo a la hora de ejecutar Doom en todo tipo de hardware:
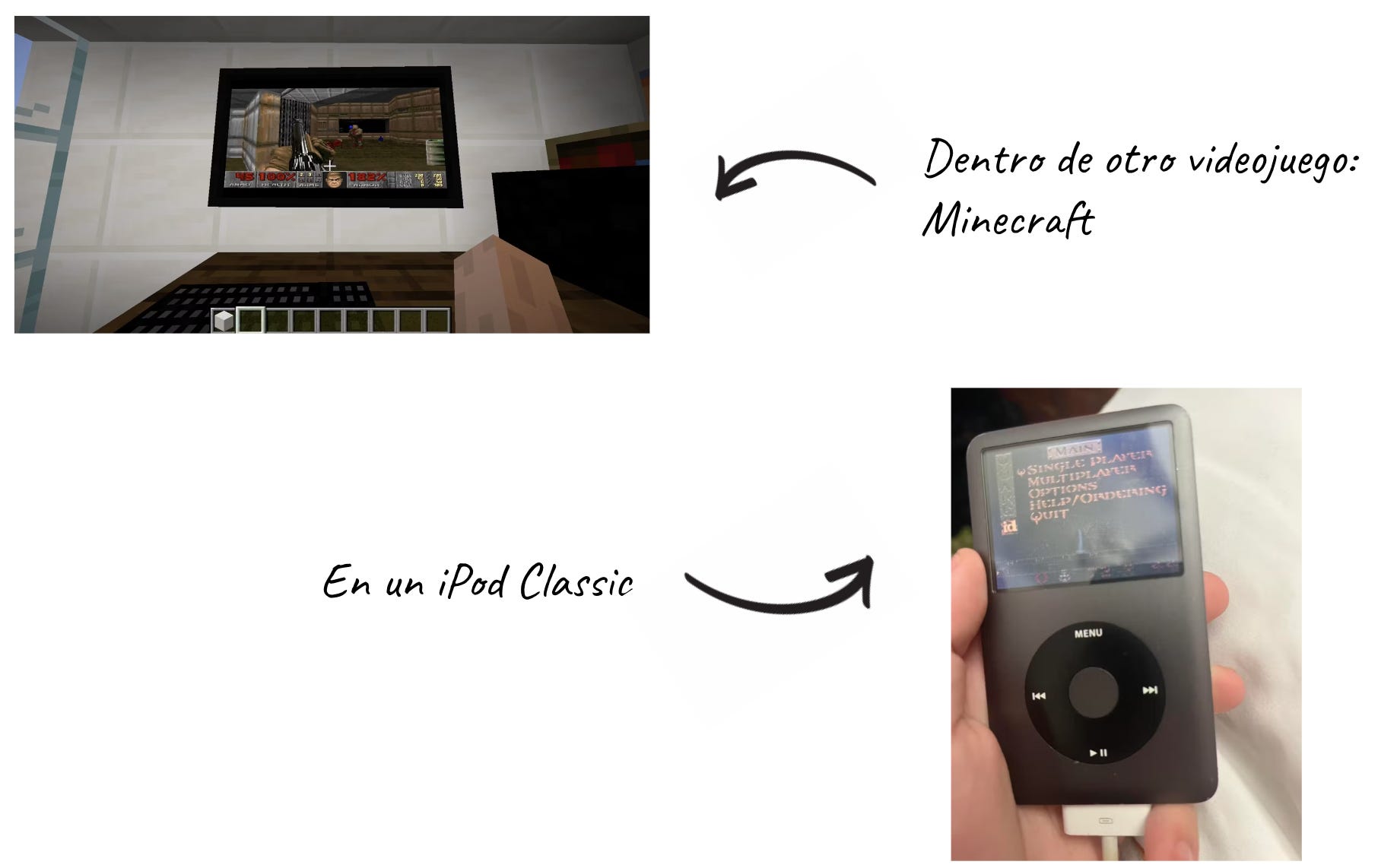
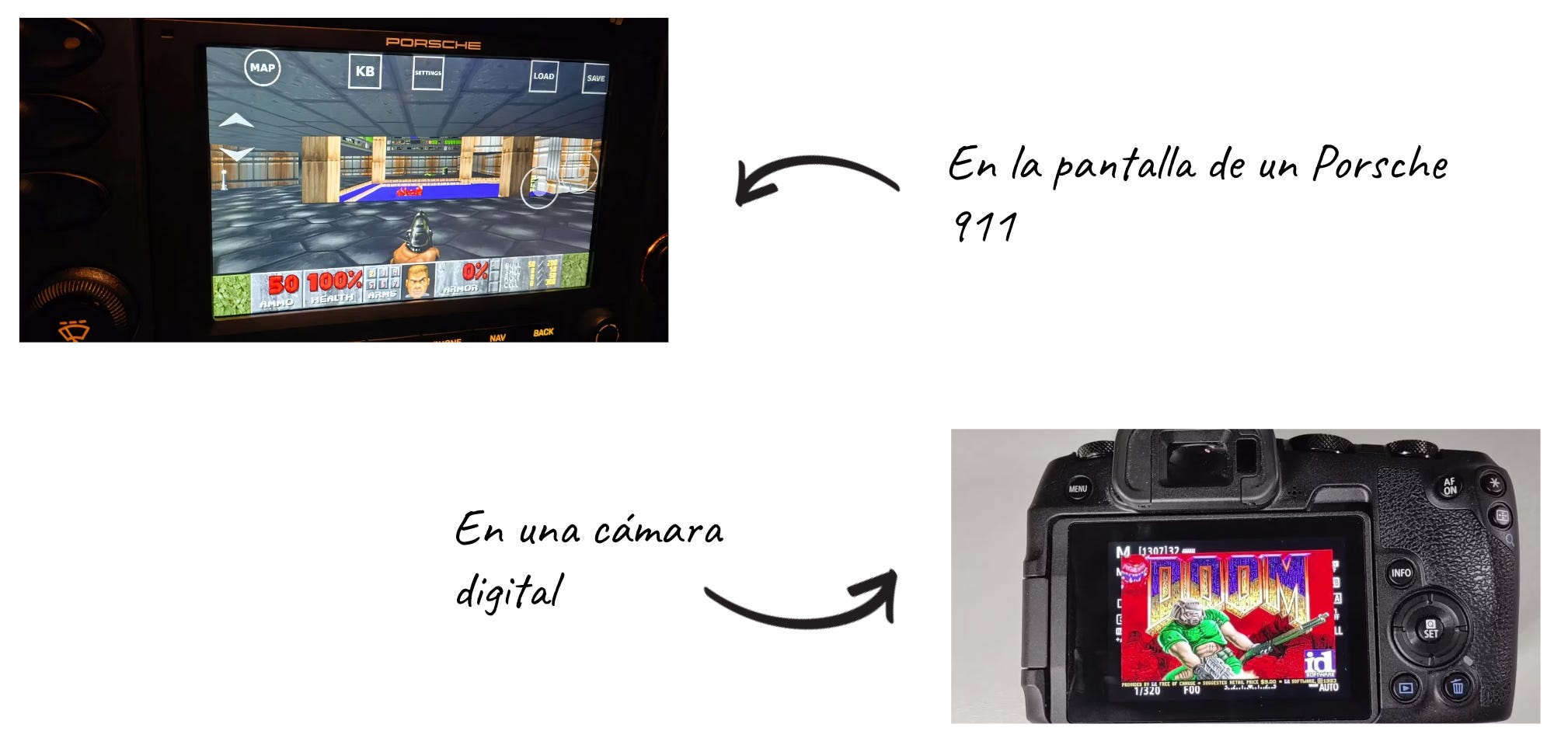
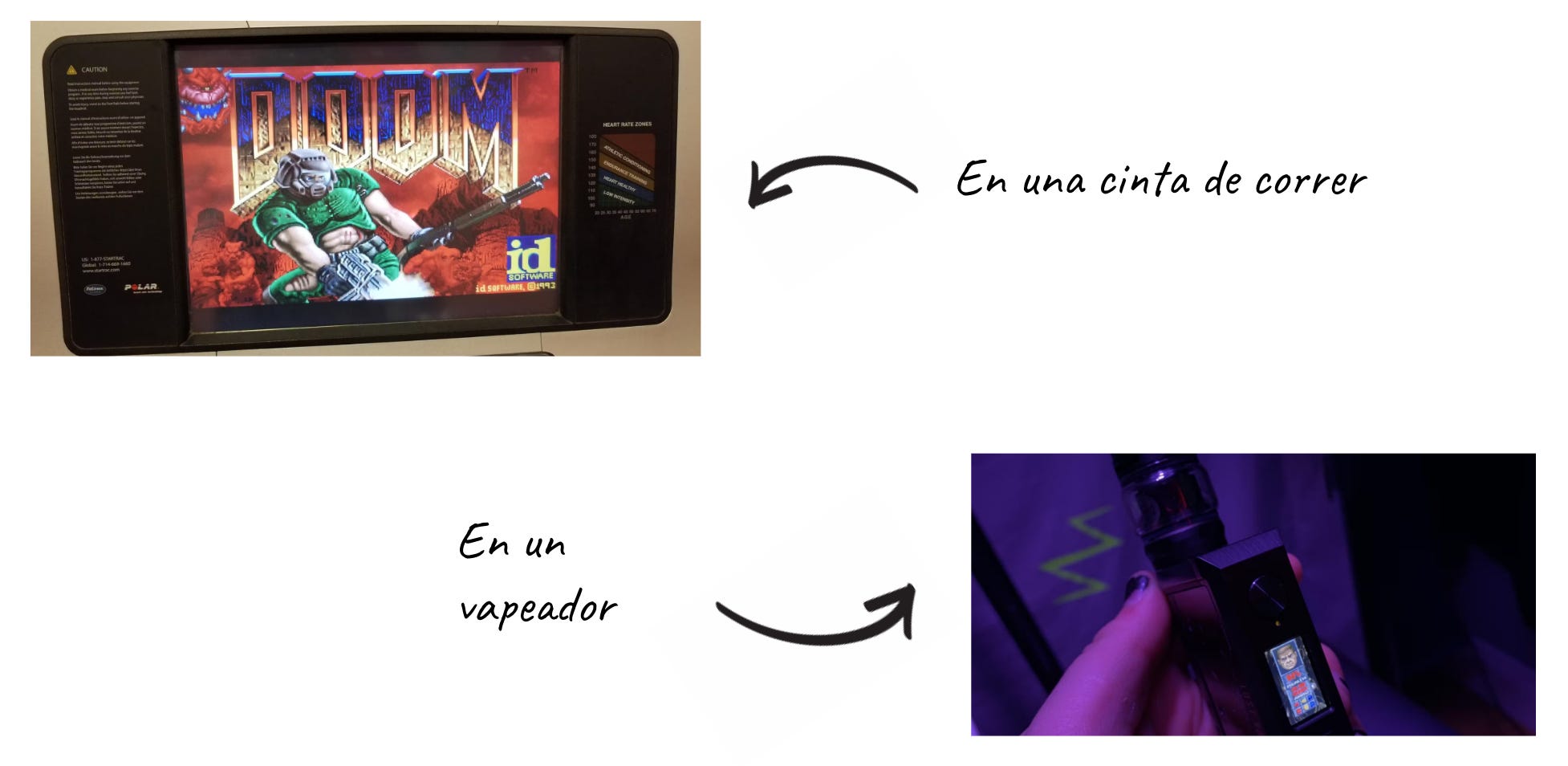
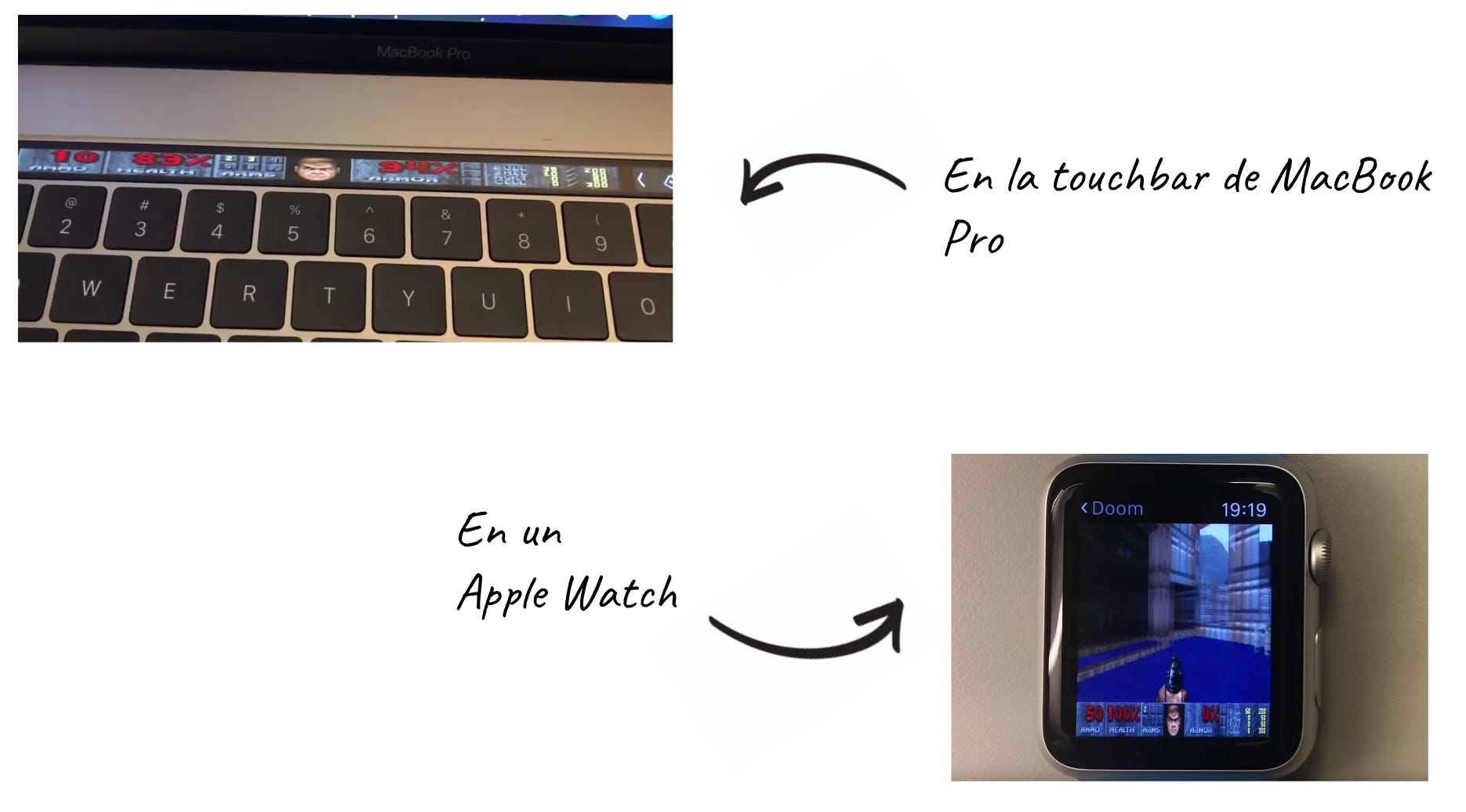
Si piensas que ya se ha llegado al límite para esta “prueba de habilidad”, basta con seguir buscando un poco más para hallar retos aún mas absurdos. Por ejemplo, puedes encontrar como un hacker pudo ejecutar Doom en un test de embarazo usando una placa auxiliar:

Y si todo esto te parece poco, las cosas se podrían tornar en aún más descabelladas ya que, después de esta publicación en la que se describe como usar cangrejos (si, cangrejos) como puertas lógicas, alguien se ha preocupado en estimar cuanto cangrejos harían falta para poder ejecutar Doom en esta hipotética bio-computadora de cangrejos 🦀

Hay muchos más ejemplos, pero prometo que acabo con este: Doom corriendo en un display volumétrico holográfico.
🖥 Reconstruyendo Doom
🔬 La ingeniería inversa
¿Y si pudiésemos replicar el motor de juego creado por Carmack y compañía para jugar a Doom sin conocer una sola línea del código original? A esta disciplina se le llama ingeniería inversa y es terriblemente complicada ya que implica hacer reconstrucciones de sistemas contando únicamente con una fracción de toda la información que sería necesaria.
Un ejemplo de ingeniería inversa, sería el trabajo de Carmack y Romero para poder replicar Mario Bros. en uno de sus primeros videojuegos.
Imaginemos la proeza más bestial de la ingeniería inversa, poder reconstruir el motor de un juego solo a través del gameplay, es decir, solo a través de la visualización de alguien jugando al juego en cuestión.
¿Sería posible algo así? Pues la respuesta es que parece que, probablemente, si lo sea.
🎨 Diffusion Models Are Real-Time Game Engines
Hace apenas unas semanas, investigadores de Google y la Universidad de Tel Aviv, publicaban un proyecto llamado GameNGen cuyo paper asociado puedes leer aquí.
Los investigadores han desarrollado un nuevo modelo de difusión capaz de simular en tiempo real el videojuego Doom usando un motor de generación de imágenes basado en Stable Diffusion.
Este hito es muy relevante. Es posible que en el futuro, los videojuegos dejen de renderizar los gráficos de manera clásica y lo empiecen a hacer usando modelos de difusión.
El modelo “alucinará” los gráficos a tiempo real como una tarea de predicción basándose en el input (moviemientos y botones pulsados) del usuario y las imágenes generadas anteriormente, dando lugar a motores capaces de crea mundos y juegos en tiempo real 🤯
Resumiendo: Los gráficos ya no se renderizarán, se alucinarán.
Dicho de otra manera, esta red neuronal que proponen los investigadores, puede funcionar como un motor (aún limitado) de videojuegos que abrirá unas puertas interesantísimas en el futuro de esta industria a través de este “Neural rendering”.
Como estarás suponiendo, el modelo fue entrenado con miles y miles de horas de gameplay de Doom por parte de humanos y de un agente de RL (Reinforcement Learning) creado para este fin:
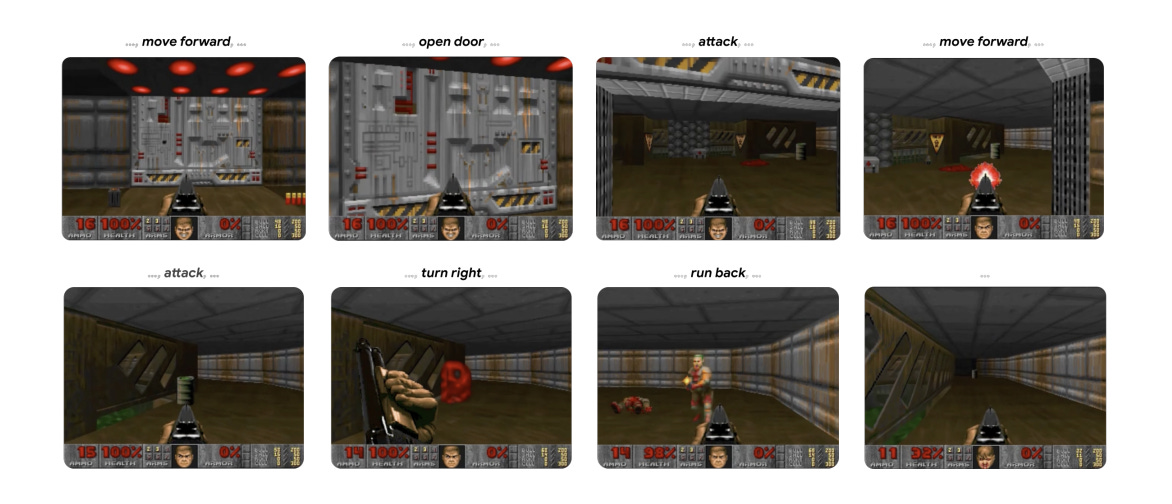
En la siguiente imagen puedes ver la arquitectura usada por los investigadores para crear este modelo:

🖼 Más allá de la imagen
Proyectos como este, junto con los avances que hemos venido viendo en síntesis de video con modelos como Sora de OpenAI, Runway Gen3 Alpha o Kling, ilustran la verdadera utilidad de los modelos de difusión.
Como ya hemos comentado en otras ocasiones, las redes neuronales son artefactos para aproximación universal de funciones y los modelos de difusión pueden ser también vistos de este modo.
Más allá de la generación de las imágenes, los modelos de difusión convenientemente entrenados son capaces de crear “modelos del mundo” o “simuladores de mundo”, ya sea este un mundo virtual -un videojuego como Doom- o nuestro mundo real.

La capacidad de estos modelos para encapsular de manera eficiente la información que define las reglas de un mundo no deja de sorprenderme y en parte asustarme ya que parece que, con suficiente computación, cualquier realidad podría ser simulable. Incluso la nuestra.
¡Gracias como siempre por leer hasta aquí!
¿Te gusta The Independent Sentinel? ¡Ayúdame a llegar a más entusiastas de la IA!
Si tienes comentarios o quieres iniciar una conversación, recuerda que puedes hacerlo aquí.
Si te has perdido alguna edición de la newsletter o quieres volver a leerlas, puedes acceder a todas aquí.
Si quieres escuchar todas las canciones de The Independent Sentinel, echa un vistazo a esta lista de Spotify.