


The Independent Sentinel #39
Domadores de modelos, herramientas que usan herramientas y una criatura mitológica

¡Hola!
Soy Javier Fuentes, de Akoios, bienvenido a una nueva edición de The Independent Sentinel, una crónica mensual sobre todo lo que está ocurriendo en el mundo de la Inteligencia Artificial y la Ciencia de Datos.
Si quieres suscribirte para recibir cada edición por email, puedes hacerlo directamente aquí:
En esta edición hablaremos de generación de imágenes, de máquinas que aprenden a usar herramientas y de una criatura mitológica.
¡Comenzamos!

🎼 Quieres banda sonora? ¡Dale al Play!
1. Tendencias 📈
✏️ ControlNet: Domando Stable Diffusion
El hecho de que ciertos modelos estén siendo liberados en modo Open Source, está sirviendo para acelerar de manera increíble la velocidad con la que estos propios modelos avanzan y van siendo mejorados.
Un ejemplo de este tipo de motores Open Source es Stable Diffusion, un modelo texto-a-imagen ya por todos conocido que, como su nombre indica, permite generar imágenes a partir de una premisa (prompt) textual.
👉🏻 Si aún no has probado Stable Diffusion, puedes hacerlo aquí
Hasta el momento, Stable Diffusion venía funcionando en modo “caja negra”, esto es, generando la imagen sin más entradas que el texto del prompt y sin permitir un mayor control del resultado obtenido.
¿Cómo se podría controlar mejor el resultado de las imágenes generadas por estos modelos?
Hace apenas unas semanas, se publicaba un paper detallando un nuevo tipo de red neuronal llamado ControlNet orientado a mejorar el control sobre los conocidos modelos de difusión, permitiendo utilizar más variables de entrada para su uso.
De manera más comprensible, podemos considerar a ControlNet como una extensión que nos permite controlar Stable Diffusion para poder generar imágenes menos arbitrarias y más cercanas a nuestras intenciones artísticas.

Si quieres ver con detalle la implementación técnica de ControlNet, puedes echar un vistazo al repositorio oficial. Si lo que te apetece es probar cómo funciona, los creadores de ControlNet han creado una serie de modelos pre-entrenados para poder jugar con ellos de manera casi inmediata a los que puedes acceder aquí. Algunos ejemplos:
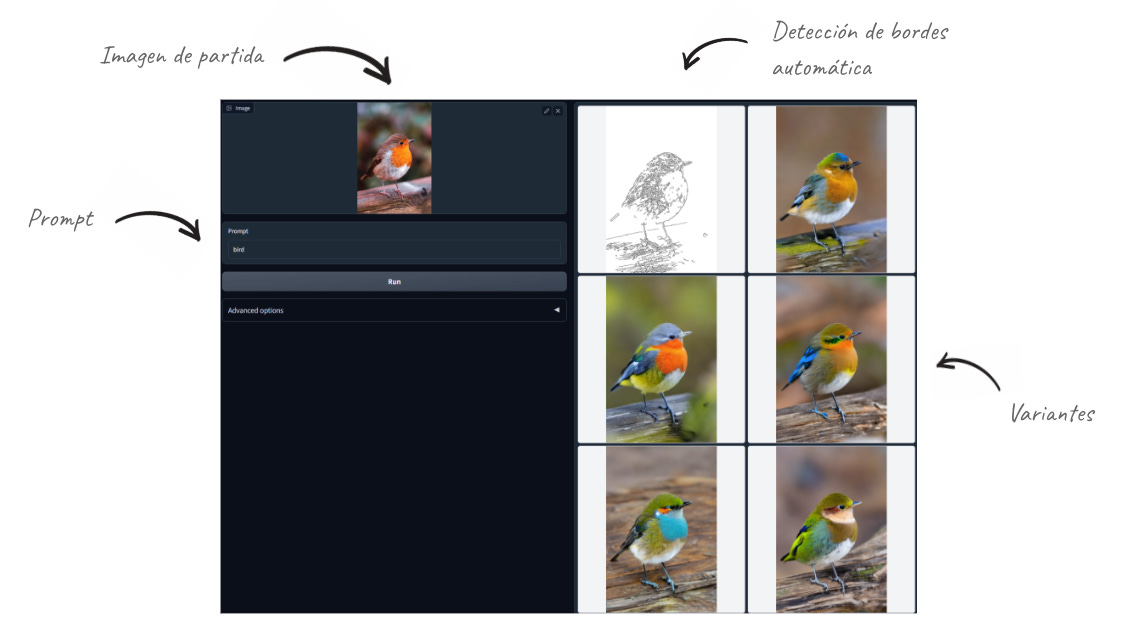
ControlNet + CannyEdge
Usando CannyEdge, es posible detectar los bordes de una imagen de entrada y, junto con un prompt arbitrario, se pueden crear variaciones “fieles” a la imagen original:
ControlNet + M-LSD Lines
De manera similar, usando Hough Line Maps se detectan líneas rectas para obtener resultados como este:

ControlNet + HED Boundary
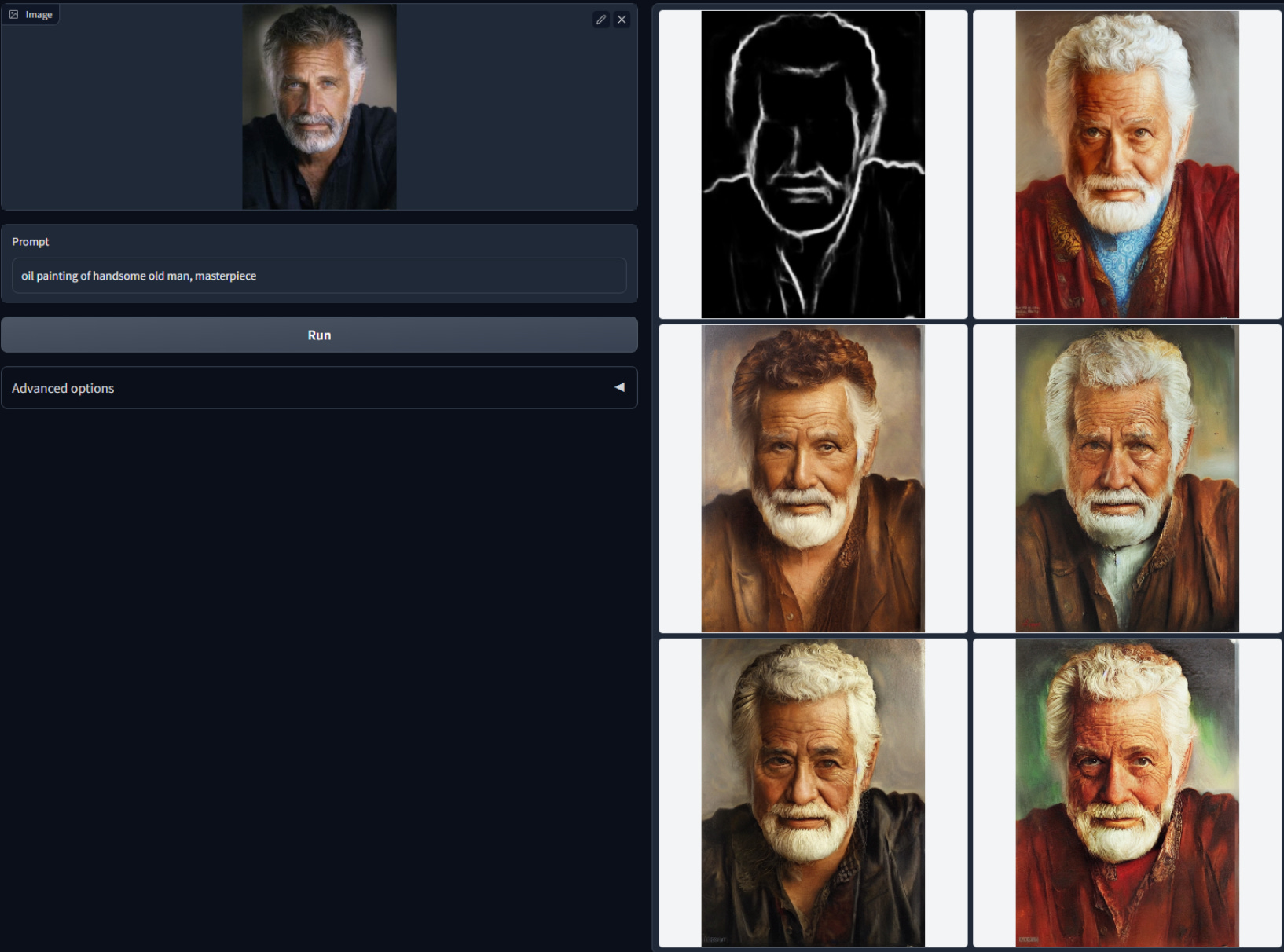
Con este modelo, se mantienen más detalles de la imagen original, haciéndolo idóneo para estilizar o recolorear imágenes. Los resultados son fantásticos:
ControlNet + User Scribbles
Esta opción es similar a herramientas como ScribbleDiffusion. En este caso, un mero sketch nos puede valer como apoyo a nuestro prompt.

A la vista de todo esto, podrías pensar que tal vez no sea tan radicalmente novedoso. Sin embargo, esto es lo que ocurre cuando pones herramientas tan poderosas en manos de una comunidad de usuarios y artistas.
En este post de Reddit un usuario muestra cómo generó una imagen fotorrealista a partir de un dibujo. Increíble:

Además ha publicado los pasos para conseguir una imagen así. Atención a la sofisticación de los prompts usados en cada fase:
Step 1 - Img2Img with the following prompt and settings:
Studying girl, best quality, ultra high res, (photorealistic:1.4), stack of books and brown flower pot on table, brown cat on white window ledgeNegative prompt: paintings, sketches, (worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, ((monochrome)), ((grayscale)), skin spots, acnes, skin blemishes, age spot, glans
Steps: 28, Sampler: DPM++ SDE Karras, CFG scale: 8, Seed: 3242059520, Size: 1024x564, Model hash: fc2511737a, Model: 20230224_chilloutmix_NiPrunedFp32Fix, Denoising strength: 0.38, Mask blur: 4
Step 2 - In-painted cat, black pen and sweater with tweaked prompt, e.g:
best quality, ultra high res, (photorealistic:1.4), back of a sleeping brown cat
Step 3 - In-painted left and right hands with Control Net (Canny)
Using the original lofi girl image as the input of the canny control net, I in-painted only the left and right hands. The canny edges detected from the original image help to correct the fingers.
Steps: 28, Sampler: DPM++ SDE Karras, CFG scale: 8, Seed: 1134728641, Size: 1024x564, Model hash: fc2511737a, Model: 20230224_chilloutmix_NiPrunedFp32Fix, Denoising strength: 0.38, Mask blur: 4, ControlNet-0 Enabled: True, ControlNet-0 Module: canny, ControlNet-0 Model: control_sd15_canny [fef5e48e], ControlNet-0 Weight: 1, ControlNet-0 Guidance Start: 0, ControlNet-0 Guidance End: 1
Step 4 - Improve details by Control Net (Depth)
Using the original lofi girl image as the input of the depth control net, we run the image to image on the last output, this improves the details on the overall image. Higher 40 steps and very low denoising strength of 0.2 is used here.
Steps: 40, Sampler: Euler a, CFG scale: 7, Seed: 3439776951, Size: 1024x564, Model hash: fc2511737a, Model: 20230224_chilloutmix_NiPrunedFp32Fix, Denoising strength: 0.2, Mask blur: 4, ControlNet-0 Enabled: True, ControlNet-0 Module: depth_leres, ControlNet-0 Model: control_sd15_depth [fef5e48e], ControlNet-0 Weight: 0.4, ControlNet-0 Guidance Start: 0, ControlNet-0 Guidance End: 1
Step 5 - Add lighting on sleeves by Control Net (Depth)
Using the latest lighting tricks i just watched from youtube, I sketched two yellow lines on the Inpaint sketch tab. With the control net depth enabled. This dramatically introduces two light sources on the girl's sleeves. Higher 60 steps and very high denoising strength of 0.8 is used here.
Steps: 60, Sampler: Euler a, CFG scale: 8, Seed: 3524037322, Size: 1024x564, Model hash: fc2511737a, Model: 20230224_chilloutmix_NiPrunedFp32Fix, Denoising strength: 0.8, Mask blur: 4, ControlNet-0 Enabled: True, ControlNet-0 Module: depth_leres, ControlNet-0 Model: control_sd15_depth [fef5e48e], ControlNet-0 Weight: 0.5, ControlNet-0 Guidance Start: 0, ControlNet-0 Guidance End: 1Como ves, esta revolución no ha hecho más que empezar.
⚒️ Toolformer: Herramientas usando herramientas
En medio de la tempestad de noticias relacionadas con la IA, hay una herramienta que, en mi opinión, ha pasado injustamente desapercibida.
En pasadas ediciones, hemos venido hablando del tremendo potencial de los grandes modelos de lenguaje, pero también de sus limitaciones a la hora de generar contenidos fiables y respuestas precisas.
Hace apenas unos días, se publicaba un interesante paper a cargo de investigadores de Meta AI y de la Universidad Pompeu Fabra titulado: “Toolformer: Language Models Can Teach Themselves to Use Tools”.
En el paper se presenta una interesantísima solución a ciertas de las limitaciones de los LLMs (Large Language Models) actuales. El modelo propuesto se ha entrenado partir de un modelo GPT-J de 6.7 millones de parámetros y tiene capacidad para identificar y usar servicios externos como:
Un sistema para responder preguntas [QA]
Un motor de búsqueda de Wikipedia [WikiSearch]
Una calculadora [Calculator]
Un calendario [Calendar]
Un sistema de traducción [MT]
A pesar de contar con un tamaño mucho menos que GPT-3, es capaz de funcionar mejor que este último debido a estas capacidades añadidas.

La solución propuesta va más allá de estas capacidades agregadas. El punto diferencial es que, con apenas algunos ejemplos de conexión facilitados externamente por un humano, el modelo puede aprender a interactuar con servicios externos a través de APIs, identificando también cuando fallan las llamadas para poder ir mejorando de manera iterativa su rendimiento.
Este acercamiento es similar al que Bing ha utilizado para su chat, complementando y mejorando las salidas del modelo con consultas externas para mejorar su precisión.
Sin, duda, este es un paso en la dirección correcta para conseguir que los LLMs sean todavía mejores y más fiables.
2. Historias 📔
👹 Una criatura de pesadilla
El Basilisco es una criatura mitológica que viene de la antigua Grecia y que sigue presente a día de hoy. El basilisco se representaba como una gigantesca y letal serpiente cargada de veneno capaz de matar solo con su mirada. Además, contaba habitualmente con una marca blanca en su cabeza a modo de diadema.
 - Deadly Serpent of Greek & Roman Legend")
Durante el medievo, la idea de esta criatura mitológica fue mutando con variaciones significativas, pasando a ser una especie de gallo con grandes alas y cola de serpiente. La razón para esta fisonomía tan especial no era otra que el propio origen mitológico de la criatura, ya que los basiliscos se originaban a partir de un huevo de serpiente incubado por un gallo.

Los basiliscos se han asociado históricamente en la tradición cristiana con el mal, la lujuria y el demonio, debido principalmente a su antinatural e impía creación.
Aparentemente invencibles, los basiliscos eran solamente vulnerables ante los gallos, las comadrejas (inmunes a su mirada y su veneno) y otras criaturas sobrenaturales.

El basilisco y todo lo que representa han seguido siendo parte de la cultura popular, como así lo atestiguan sus apariciones en Ricardo III de Shakespeare, en el Drácula de Bram Stoker o, más recientemente, en las novelas y películas de Harry Potter.

🐲 El Basilisco de Roko
En 2014 David Auerbach mencionaba por primera vez el concepto de “Basilisco de Roko” categorizándolo como el experimento mental más terrorífico de la historia en este famosísimo artículo.
La historia comenzó en LessWrong, un foro de Internet creado por un teórico de la IA (Eliezer Yudkowsky) y un economista (Robin Hanson) en el que se tratan temas tan variados como la economía, la filosofía, los sesgos cognitivos, la psicología, la teoría de la decisión, el transhumanismo o la Inteligencia Artificial.
Cabe destacar que Yudkowsky dirige también el llamado Machine Intelligence Research Institute un Instituto de Investigación dedicado a identificar y gestionar los peligros existenciales de la AGI (La Inteligencia Artificial General) y, sobre todo, a desarrollar el concepto de IA Amigable, una AGI benigna que contribuya a al avance de la humanidad. Este Instituto está financiado por viejos conocidos de esta newsletter como Peter Thiel y Ray Kurzweil.
Pero volvamos a la historia. El 23 de Julio de 2010, “Roko”, uno de los usuarios de este foro, publicó un inquietante experimento mental en el que planteaba lo siguiente:
Un sistema futuro benevolente de Inteligencia Artificial podría decidir torturar a aquellos que, siendo conscientes en el pasado de la posibilidad de crearla, no trabajasen sin descanso para hacerla realidad cuanto antes y ayudar así a al humanidad.
El problema que plantea es que, una máquina programada para hacer el bien, podría llegar a tomar decisiones extremas. Al darse cuenta de que para hacer el bien debería haberse creado antes evitando así sufrimiento humano, podría decidir comportarse como un “Basilisco”, castigando a todos aquellos que no trabajaron de manera incansable para haberla creado antes 🤯
Como bien explicaba el periodista Dylan Love, la parte más aterradora es que, si no estás ayudando ya al avance de la IA, te estás significando como una víctima potencial de su venganza. En palabras del propio Love:
"Más te vale que ayudes a los robots a hacer del mundo un lugar mejor, porque si los robots descubren que no ayudaste a hacer del mundo un lugar mejor, te matarán por impedirles que hagan del mundo un lugar mejor. Al impedirles que hagan del mundo un lugar mejor, ¡estás impidiendo que el mundo se convierta en un lugar mejor!".
👉🏻 Si tienes curiosidad, puedes ver una copia del post original aquí.
En el post original, Roko profundiza en su planteamiento, usando marcos teóricos creados por el propio Yudkowsky (el creador del foro) como la TDT (la teoría de la decisión atemporal). En la publicación especifica incluso cómo sería la tortura a la que sería sometidos los no colaboradores:
The torture itself would occur through the AI's creation of an infinite number of virtual reality simulations that would eternally trap those within it.
Y sobre todo, la parte más inquietante:
El mero hecho de conocer y expandir esta teoría, estaría dando incentivos de la IA para chantajearnos.
A todos los lectores de LessWrong se les estaba planteado una decisión: a) ayudar a las máquinas o b) sufrir una condena eterna.
Varios usuarios de LessWrong reconocieron haber tenido pesadillas por esta conjetura, pero la polémica llegó cuando el propio Eliezer Yudkowsky respondió al mensaje de manera inesperadamente agresiva:
Listen to me very closely, you idiot.
YOU DO NOT THINK IN SUFFICIENT DETAIL ABOUT SUPERINTELLIGENCES CONSIDERING WHETHER OR NOT TO BLACKMAIL YOU. THAT IS THE ONLY POSSIBLE THING WHICH GIVES THEM A MOTIVE TO FOLLOW THROUGH ON THE BLACKMAIL.
You have to be really clever to come up with a genuinely dangerous thought. I am disheartened that people can be clever enough to do that and not clever enough to do the obvious thing and KEEP THEIR IDIOT MOUTHS SHUT about it, because it is much more important to sound intelligent when talking to your friends.
This post was STUPID.— Eliezer Yudkowsky, LessWrong
Seguidamente, Yudkowsky borró la publicación de Roko, consiguiendo justo el efecto contrario: un escrito en un foro minoritario se convirtió en una leyenda urbana que, eventualmente, muchos hemos llegado a conocer: “El Basilisco de Roko”.
♟ El juego de Newcomb
Como suele ocurrir en los experimentos mentales, lo que aparentemente es un juego acaba encerrando algún dilema sobre asuntos trascendentales. En este caso, el fondo del asunto tiene que ver con la filosofía moral y la teoría de la decisión.
En la filosofía y en las matemáticas existe un concepto llamado “La Paradoja de Newcomb”. Esta paradoja plantea en un juego entre dos jugadores con una particularidad muy especial: uno de ellos es capaz de predecir el futuro y nunca se equivoca.
La formulación del juego es sencilla:
En este juego hay dos participantes: un “superjugador” capaz de predecir el futuro y un jugador normal. Al jugador normal se le presentan dos cajas: una abierta que contiene $1.000 y otra cerrada que puede contener $1.000.000 o bien $0. El jugador debe decidir si prefiere recibir el contenido de ambas cajas o solo el de la caja cerrada.

¿Escogerías la caja cerrada o ambas cajas?
Si te pones a pensarlo empezarás a notar un dolor de cabeza importante debido a que el juego lleva a una autocontradicción relacionada con la existencia -o no- del libre albedrío.
📖 Profecías autocumplidas
Pero, ¿qué tiene que ver todo esto con el Basilisco de Roko? Pues que, tal vez, el Basilisco no sea más que una reformulación de la paradoja de Newcomb.
El Basilisco de Roko te ha dicho que si coges la caja B, tendrás sufrimiento eterno porque lo que realmente quiere es que cojas la caja A y la caja B.
En este caso, la decisión racional será dedicar tu vida a crear a esta IA ya que, si finalmente llega a crearse y tú no has ayudado a ello, estarás jodido.
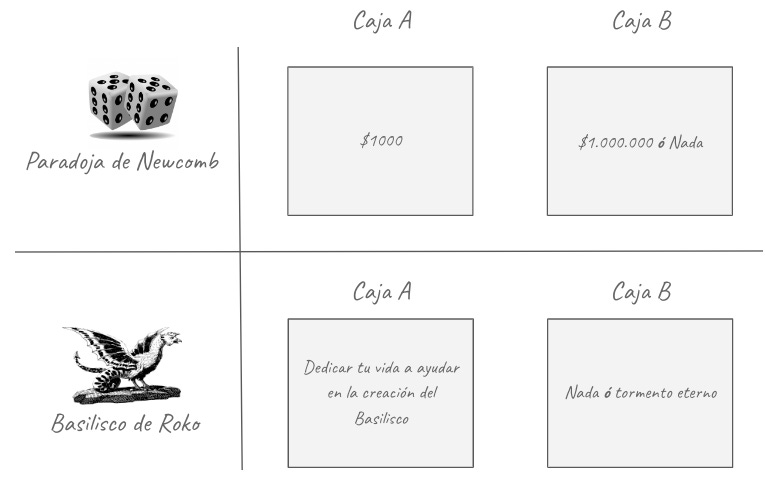
Veamos con más detalle la paradoja de Roko. Como hemos visto, partimos del supuesto de que una Super AGI consigue la habilidad para moverse en el tiempo e influir en su propia creación.
Esta superinteligencia, otorga a las personas dos alternativas:
Escoger las cajas A y B: Ayudar a la creación y no recibir nada
Escoger la caja B: Recibir tortura eterna en una simulación de Realidad Virtual
Es conveniente recordar que la Super IA ya sabe lo que vas a elegir y que nunca se ha equivocado, por lo que, si no la ayudas, te someterá a un tormento digital eterno 😵

Como se ve en la matriz de juego, la opción racional es escoger siempre ambas cajas ya que, no hay nada bueno que puedas conseguir al escoger solo la cerrada. Esta, de hecho, suele ser la decisión considerada racional en la paradoja de Newcomb.
A la vista de esto, el miedo de Yudkowsky no es estricamente si esta situación llegará a ocurrir sino que, como si fuese una profecía autocumplida, pensar en este tipo de acuerdos hace que sea más probable que ocurran.
Si el basilisco de Roko viese que este chantaje pudiera ser útil para conseguir ser creado antes, lo racional por su parte sería llevarlo a cabo.
Si has conseguido llegar hasta aquí sin que te explote la cabeza, vamos a ver cómo este debate no es tan nuevo como podría parecer.
Muchos afirman que el “Basilisco de Roko”, no es más que una actualización de la llamada “Apuesta de Pascal” planteada por el celebérrimo Blaise Pascal en el Siglo XVII.

La “Apuesta de Pascal” viene a decirnos que, para una persona racional, tiene sentido creer en Dios ya que a expensas de una pérdida finita (e.g. pérdida de posesiones) es posible optar a una ganancia infinita (el “Cielo”).
En el caso del “Basilisco de Roko”, lo racional para la humanidad es intentar crear esa AGI con el precio acotado del coste de oportunidad que esto conlleva pero con la ventaja infinita de evitar una tortura eterna.
Si lo piensas, la pregunta es la misma solo que hemos cambiado a Dios por una Inteligencia Artificial omnisciente. Un claro reflejo del signo de nuestros tiempos.
Aparte de estas similitudes, la verdadera cuestión que se plantea es aún más compleja que las planteadas hasta el momento: Si fuésemos capaces de crear un dios, ¿cómo nos podríamos asegurar de que fuese benigno para los humanos?
¡Gracias como siempre por leer hasta aquí!
¿Te gusta The Independent Sentinel? ¡Comparte esta publicación para ayudarnos a llegar a más gente!
Si tienes comentarios o quieres iniciar una conversación, recuerda que puedes hacerlo aquí.
Si te has perdido alguna edición de la newsletter o quieres volver a leerlas, puedes acceder a todas aquí.
👉 ¿Te gustaría trabajar en IA y Ciencia de Datos? Escríbenos a team@akoios.com
Gracias Javier, un artículo genial!