


The Independent Sentinel #17
Aplicaciones industriales, un generador de modelos y los bloques de la vida.

¡Hola!
Soy Javier Fuentes, de Akoios. Bienvenido a la última edición de este año de The Independent Sentinel, la newsletter dedicada a hablar de curiosidades, novedades e historias sobre -casi siempre- Ciencia de Datos.
Si quieres suscribirte, puedes hacerlo fácilmente pulsando en el botón de abajo:
Hoy hablaremos de Casos de Uso de Machine Learning en la industria, de generación automática de modelos y del plegamiento de las proteínas.

¡Comenzamos!
🎼 ¿Quieres banda sonora? ¡Dale al Play!
1. Ciencia de Datos
Casos de uso ⚙️
Una de las labores clave de cualquiera que se dedique a la Ciencia de Datos es poder identificar Casos de Aplicación en su ámbito de trabajo. Esto no es trivial ya que, la naturaleza transversal de esta disciplina, hace que pueda ser aplicada en todos los sectores para muy diversos fines.
Trabajar sobre estos Casos de Aplicación o Casos de Uso es vital ya que ayuda a que todos aquellos no familiarizados con nuestro mundo puedan entender para qué les podría servir usar los datos en su proyecto o negocio.
En este sentido, en FirmAI han creado un repositorio centralizado y open-source de casos de uso en todo tipo de sectores, desde salud hasta finanzas:

Puedes ver aquí la lista completa de los casos de uso o directamente en esta hoja de cálculo compartida donde, además, es posible añadir casos por parte de cualquiera que quiera colaborar. La parte más interesante es que la mayoría de los Casos de Uso vienen con código fuente incluido (normalmente en Jupyter Notebooks),
👉 Si quieres poner en productivo cualquiera de estos modelos a nivel industrial/corporativo, no tienes más que ponerte en contacto con nosotros en info@akoios.com y te contaremos más sobre nuestra herramienta Titan. También puedes solicitar un acceso gratuito para probar nuestro producto aquí.
Herramientas ⚡️
El scaffolding (andamiaje en español) es el nombre que se da en programación al proceso de generar plantillas de código para crear automáticamente el esqueleto de una aplicación.
Estas herramientas son tremendamente comunes en el mundo del software tradicional y, poco a poco, van apareciendo también en el terreno del Machine Learning.
Un ejemplo es Train Generator, una herramienta que permite generar plantillas de código para PyTorch y Scikit-learn a partir de una sencilla interfaz Web. Train Generator permite seleccionar fácilmente las opciones del modelo para crear automáticamente el código ya listo para ser personalizado.

Además, permite exportar el modelo creado a Python, Jupyter Notebook o Google Colab.
Puedes probarlo aquí: https://traingenerator.jrieke.com/
2. Historias 📔
El plegamiento de las proteínas
Las proteínas son los bloques esenciales de la vida. Estas moléculas complejas son cadenas de aminoácidos que tienen una propiedad muy especial: Su función depende en gran medida de la forma (estructura en 3D) que acaben adoptando, proceso denominado como plegamiento de proteínas (protein folding en inglés).
Viajemos atrás en el tiempo antes de continuar. En la ceremonia de aceptación de su Premio Nobel en Química en 1972, Christian Anfinsen postuló que, teóricamente, la secuencia de aminoácidos de una proteína en 1D debería definir su estructura 3D de forma determinista.

La afirmación de Anfinsen planteaba un reto nada desdeñable ya que, una proteína típica puede plegarse en 10³⁰⁰ formas distintas 🤯. Cyrus Levinthal, la persona que realizó esta estimación, calculó que llevaría más tiempo que la edad del universo enumerar todas las posibles combinaciones por fuerza bruta.
La llamada paradoja de Levinthal se refiere a que, pese a la increíble cantidad de posibilidades, las proteínas se pliegan en apenas unos pocos milisegundos.
Predecir cómo se plegará una cadena en la intrincada forma final de una proteína es el llamado “protein folding problem”, problema en el que se ha venido trabajando desde el planteamiento de Anfinsen hace casi 50 años.
Resolver este problema tiene implicaciones muy profundas ya que, si entendemos cómo se determina la estructura de la proteína a partir de su secuencia, se puede determinar también su uso. Esto abriría la puerta al diseño de nuevos medicamentos y comprender mucho mejor infinidad de procesos biológicos. Sin duda, un avance sin precedentes.
Durante estas últimas cinco décadas, los investigadores han analizado estas formas de manera experimental usando técnicas como la resonancia nuclear magnética, cristalografía de rayos X o microscopia cryo-electron, todas ellas técnicas válidas pero tremendamente lentas y costosas.
Por ello, y como no podía ser de otra forma, el software empezó a jugar un papel importante en esta búsqueda con iniciativas como BlueGene abanderada por IBM.
Tal ha sido el interés en este campo que, desde 1994, se celebra un concurso denominado CASP (Critical Assessment of Protein Structure Prediction) para catalizar, compartir y monitorizar los avances en las técnicas predictivas de plegamiento de proteinas.
Aquí llega la parte interesante que, además, es un ejemplo fantástico de cómo el saber y los avances se van “componiendo” y superponiendo para abrir puertas que habían estado cerradas hasta ahora.
Gracias a los avances en el secuenciamiento genético y su consiguiente abaratamiento, se ha ido disponiendo de más y más información genoma. Como era de esperar, esto ha ido propiciando la paulatina entrada de técnicas de Machine Learning en CASP.
La edición de este año, la CASP14, ha sido diferente y por una muy buena razón.
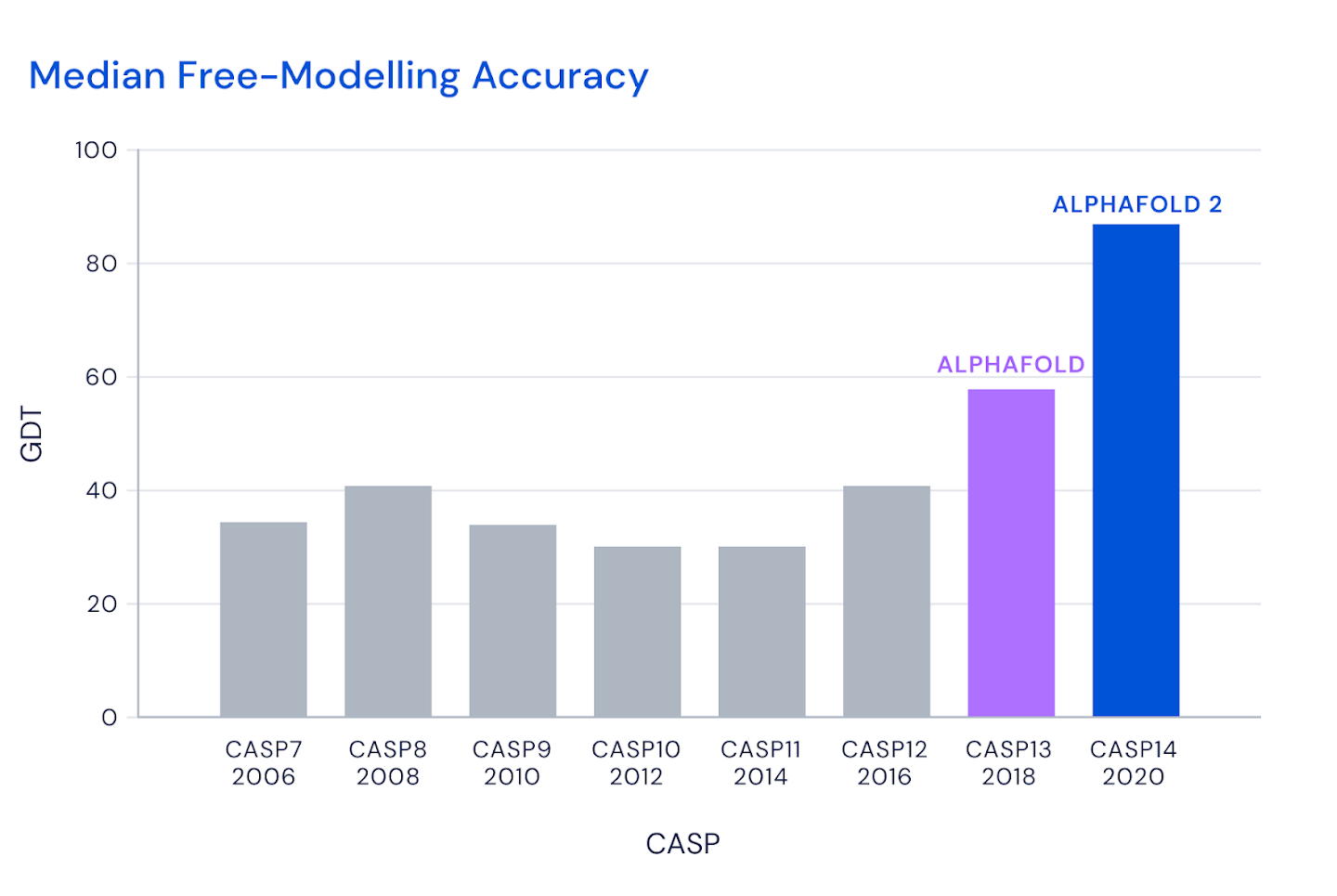
El sistema AlphaFold 2 desarrollado por DeepMind (Google) ha obtenido unos resultados espectaculares, consiguiendo predicciones muy similares a las observables de manera experimental, pero con un coste y en un tiempo órdenes de magnitud menores.

Como se puede ver en la imagen (fuente), la predicción es casi exactamente igual a la predicción. En el cómputo global, casi 2/3 de las predicciones de AlphaFold 2 son indistinguibles de las observaciones experimentales.
AlphaFold 2 es una red neuronal (de la que todavía no se han desvelado detalles sobre su estructura interna) entrenada con las secuencias y estructuras de más de 170000 proteínas conocidas usando 16 TPUv3s de Google (equivalentes a 100-200 GPUs) durante varias semanas.
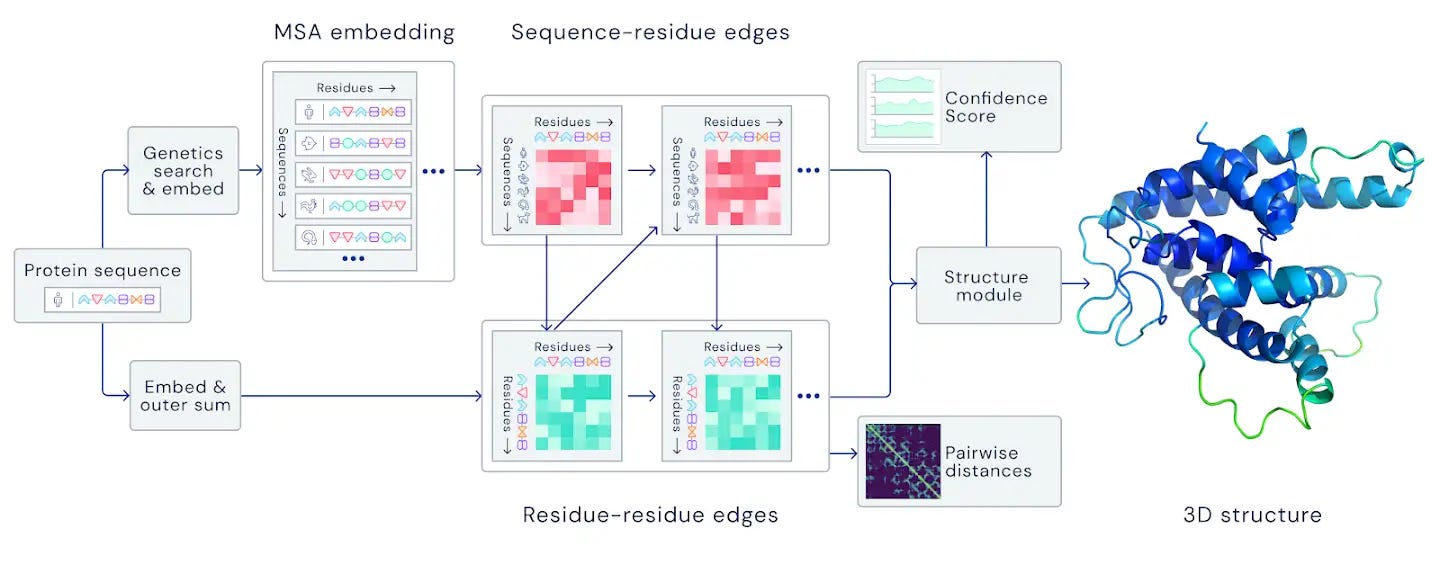
Además de las implicaciones ya mencionadas, este hito supone un espaldarazo muy importante para el Machine Learning. Los años de investigación, todos los antecedentes (algunos aparentemente triviales como los modelos que juegan al Go o al ajedrez) y los miles de investigadores que han hecho aportaciones de un modo u otro, han cristalizado en un software que ha resuelto un problema increíblemente complejo e importante. Lo mejor de todo es que parece que este tipo de avances en biomedicina no han hecho más que empezar.
No hay duda de que 2020 ha sido un año terrible. Pese a ello, avances como este o como la reciente vacuna con tecnología mRNA nos deberían hacer sentirnos optimistas respecto al futuro. Nunca antes en la historía hemos tenido el ritmo de avance científico y tecnológico que tenemos ahora y este ritmo no hará más que incrementarse.
Por ello, y pese a todo, always look on the bright side of life. ¡Gracias por leernos!

🎉 ¡Feliz año para todos! 🎊 (Casi) seguro que este 2021 será mejor.
¿Disfrutas The Independent Sentinel? Échanos una mano compartiendo nuestra publicación con todos aquellos a los que creas que le pueda gustar esta newsletter.
Si tienes comentarios o quieres iniciar una conversación, recuerda que puedes hacerlo al final de la publicación.
Si te has perdido alguna edición de la newsletter, puedes leer todas aquí.
👉 Si quieres conocer mejor cómo funciona nuestra tecnología Titan, no te pierdas nuestra serie de tutoriales publicados en Medium.
👉 Si te interesa, puedes solicitar un acceso gratuito para probar Titan aquí https://lnkd.in/gPz-2mJ